Product
Why biomedical AI fails at retrieval before it fails at reasoning
A 10-question benchmark across Amass BioMedCore, Claude with PubMed, and ChatGPT with web search. Retrieval, not reasoning, is biomedical AI's bottleneck.
- Product
- Technical
Most AI systems in science do not fail because they cannot generate an answer. They fail because they begin reasoning from too little evidence.
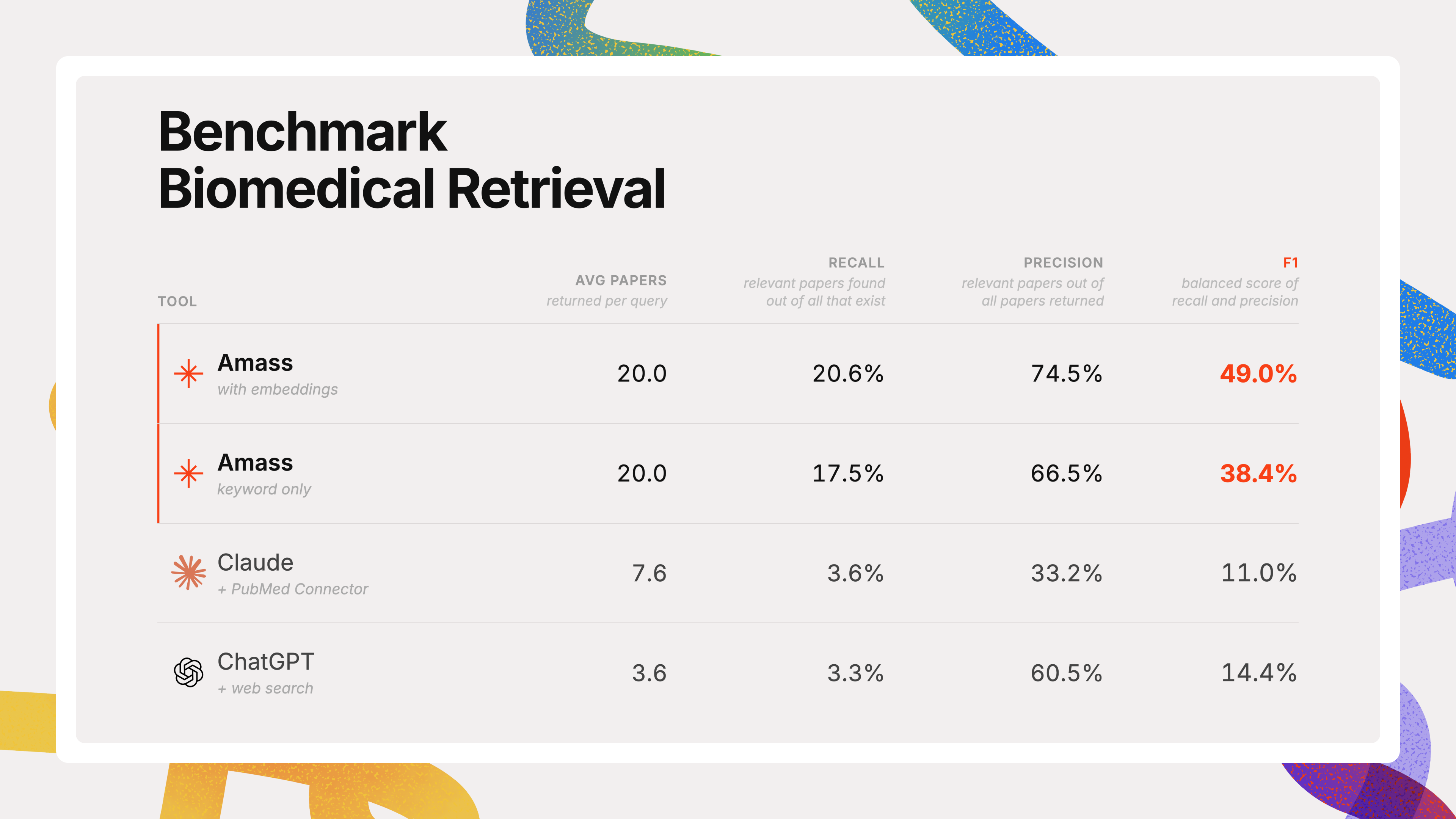
We tested ten realistic biomedical questions — the kind clinicians and researchers bring to the Amass platform every day — across four setups: Amass BioMedCore search with embeddings, Amass BioMedCore search without embeddings, Claude with the PubMed connector, and ChatGPT with web search.
Then we checked how many of the known-relevant papers each system actually surfaced.
The result was consistent: Amass returned a broader and more relevant body of literature for every question. The main reason was not better generation. It was better retrieval. Amass treats "find me the papers" as a first-class retrieval problem and returns a full, configurable evidence set before synthesis begins. General-purpose chat tools surface a smaller and more variable citation set as part of answering, which limits what a downstream agent can actually reason over.
TL;DR
We asked ten realistic biomedical questions and handed each one to four tools: Amass BioMedCore search with embeddings, Amass without embeddings, Claude with the PubMed connector, and ChatGPT with web search.
We then evaluated how many known-relevant papers each system surfaced.
The short version: Amass surfaced a much broader and more relevant evidence set per question than the general-purpose chat tools. That does not mean the reasoning model is inherently smarter. It means the retrieval layer is doing a fundamentally different job.
Amass always returns a full set of 20 papers by default, which can be configured. Claude and ChatGPT surfaced far fewer papers on average, and because of that they missed most of the relevant literature along the way.
For downstream AI agents, that difference matters. An agent can only synthesize across the papers it actually sees.
The scorecard
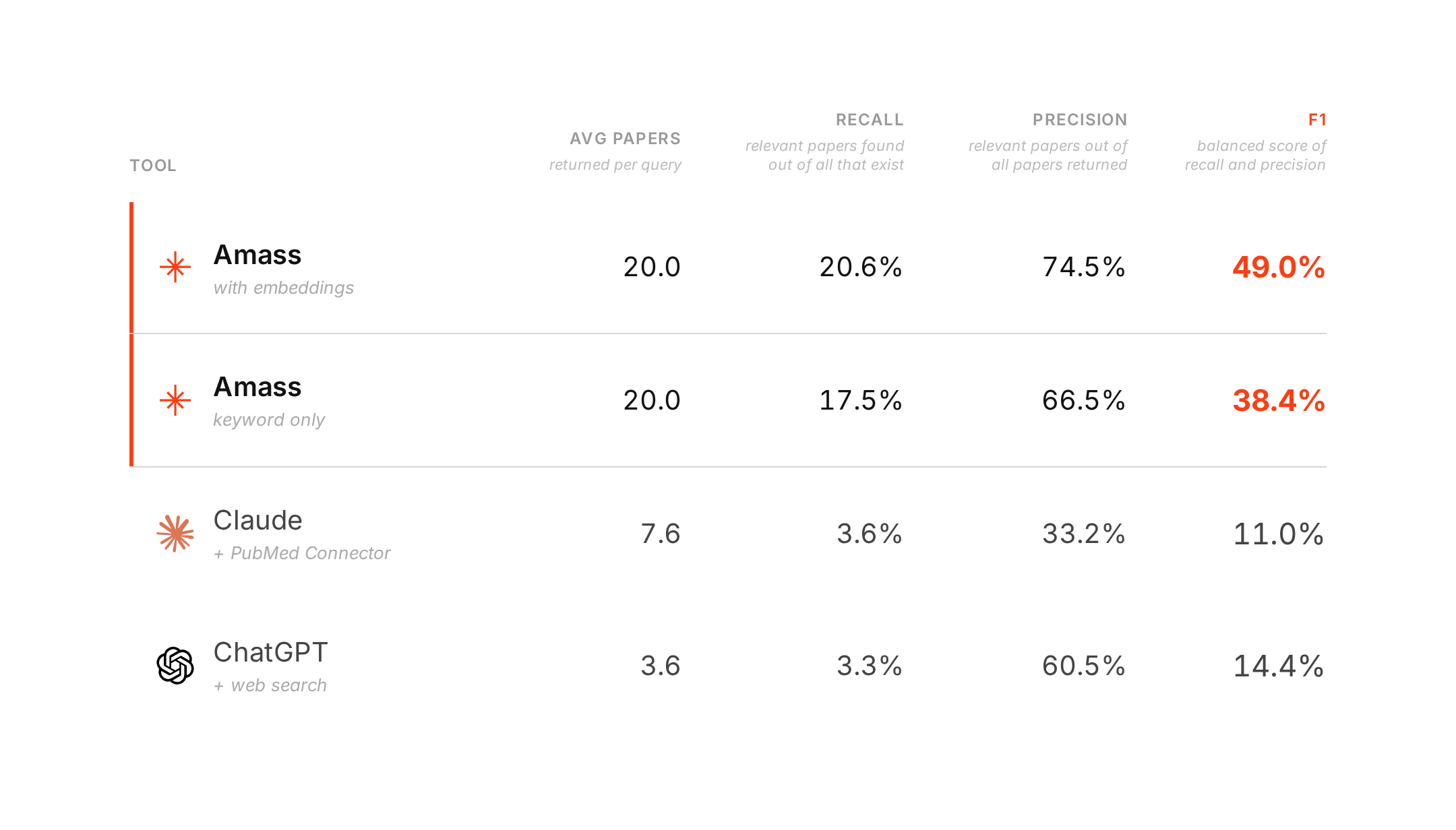
The difference in result depth matters here. Amass returned 20 papers per question. Claude surfaced 7.6 on average. ChatGPT surfaced 3.6.
The scorecard in plain English
Recall asks: of all the papers we know are relevant, how many did the system actually find?
Precision asks: of the papers the system returned, how many were actually relevant?
F1 rewards systems that do both well. It is a single measure of whether the tool did the retrieval job in a balanced way.
ChatGPT's precision looks decent at first glance. But that number is partly a function of how few papers it returns. If a tool only surfaces 2–4 citations, precision can look respectable even while it misses most of the literature. That is why its F1 remains low.
Why this matters for AI agents
A downstream agent can only reason over the evidence it actually sees.
If a system returns 3–4 papers, the downstream agent reasons over 3–4 papers. If it starts from a dense, relevant set of 20 papers, it can compare, contrast, rank, and synthesize across a real body of evidence.
That is the difference we see here.
Amass consistently retrieves a full evidence set up front. General-purpose chat products surface a smaller and more variable citation set as part of producing an answer. That may work well for conversational use. It is much less reliable when the goal is structured scientific analysis.
If a downstream agent is supposed to build a clinical rationale, a literature landscape, or a structured comparison across trials, 2 or 3 papers is often not enough. And because the number of surfaced citations varies so much from question to question, you do not know in advance where the retrieval layer will fall short.
One especially important finding is that even Amass's keyword-only configuration — with no semantic embeddings at all — still outperformed the general-purpose tools on every question and on every headline metric.
Why specialized retrieval is key
1. Retrieval happens before synthesis
Amass performs retrieval explicitly before synthesis, over a purpose-built biomedical index. That means the system first focuses on assembling the evidence set, and only then hands those papers to a reasoning model.
General-purpose chat products are designed primarily to produce an answer, with citations attached as part of that process. That makes them useful conversational tools, but it often leads to thinner evidence coverage.
2. Meaning matters, not just keywords
The embedding model represents papers in a semantic space, where conceptually similar work sits close together even when the wording differs.
So a question about lipid metabolism in the tumor microenvironment can still retrieve papers framed as fatty-acid reprogramming in cancer stroma, even if the exact language does not match. Keyword search alone often misses that kind of overlap.
3. Ranking is tuned for scientific usefulness
Amass does not just retrieve papers. It ranks them using signals that matter in biomedical work, including study type and source quality.
A well-designed randomized study in a strong journal should usually rank above a weaker or less relevant paper, and the retrieval layer accounts for that.
4. The result set is fixed and dependable
Amass returns 20 papers every time by default. That consistency matters when another AI system has to consume the output downstream.
A variable set of 1, 3, or 8 citations may still produce a plausible answer, but it is a much less dependable input for structured scientific workflows. With the Amass API, that set can also be configured depending on the use case.
Per-question highlights
Precision, recall, and F1 are all macro-averaged across questions — each question contributes equally to the headline numbers above.
| Question | Amass (embed + keyword) F1 | Amass (keyword-only) F1 | Claude F1 | ChatGPT F1 |
|---|---|---|---|---|
| Q4 — Immunotherapy in early-stage vs advanced NSCLC | 37.5% | 34.1% | 8.0% | 13.0% |
| Q5 — Lipid metabolic reprogramming and cancer immunotherapy | 36.4% | 28.6% | 0.0% | 5.6% |
| Q6 — Delivery vs expectant management in late-preterm preeclampsia | 71.6% | 47.7% | 44.4% | 18.2% |
| Q7 — Tralokinumab efficacy in moderate-severe asthma | 67.7% | 50.7% | 26.1% | 28.6% |
| Q8 — Anti-TNF immunogenicity in rheumatoid arthritis | 50.0% | 39.8% | 9.1% | 19.5% |
| Q9 — Childhood eczema and patch-test contact allergy | 32.7% | 32.3% | 11.1% | 0.0% |
| Q10 — Dopamine agonists vs SSRIs for depression in Parkinson's | 67.8% | 55.0% | 0.0% | 16.7% |
| Q11 — Ranibizumab in neovascular AMD: phakic vs pseudophakic (ANCHOR/MARINA) | 51.9% | 37.5% | 0.0% | 33.3% |
| Q12 — Antiretroviral regimens for preventing mother-to-child HIV transmission | 34.5% | 25.1% | 8.8% | 6.2% |
| Q13 — GLP-1 receptor agonists: GI safety vs efficacy across doses | 40.1% | 33.5% | 2.8% | 2.9% |
Amass with embeddings was the top system on every one of the ten questions. So was Amass without embeddings.
The biggest gaps showed up on clinical-decision questions with a meaningful evidence base: preeclampsia, tralokinumab in asthma, and dopamine agonists versus SSRIs in Parkinson's depression. These are exactly the kinds of settings where downstream evidence coverage matters.
One especially striking example was Q11, on ranibizumab outcomes in neovascular AMD. On that narrow question, Amass with embeddings found every highly graded paper in the ground truth. Claude surfaced a single paper that was not relevant. ChatGPT surfaced two papers. When an evidence base is narrow enough to be covered exhaustively, coverage becomes visible very quickly.
On the broader oncology questions, every tool struggled. But even there, the difference in retrieval depth remained important. Amass still returned 20 papers, while the general-purpose tools surfaced much smaller sets. That meant the downstream agent still had materially more evidence to work from.
What this means for users
When an Amass agent answers a biomedical question, it is working from a consistent, dense body of literature — not a handful of citations surfaced on the way to producing an answer.
Those 20 papers are not perfect. Our recall against a hand-curated ground truth is still in the 17–21% range, and the ground truth itself is imperfect. But the shape of the answer is fundamentally different.
It is grounded in a broader and more dependable evidence base.
That is why specialized retrieval matters, and why it will keep mattering even as large language models improve. A brilliant reasoner working from three papers is still limited by those three papers.
Caveats
Small sample
This is a ten-question benchmark. It is directional, not definitive. It should be read as a realistic product evaluation, not as a universal scientific benchmark.
Imperfect ground truth
The known-relevant papers come primarily from systematic review reference lists and pooled enrichment strategies. That is a strong starting point, but it does not capture every paper a user might reasonably consider relevant. Absolute recall numbers therefore understate real-world usefulness.
General-purpose tools can still pick good papers
This comparison is not saying Claude or ChatGPT are incapable of surfacing useful biomedical evidence. On some questions, especially narrower ones, they did return good papers. The main weakness we observed was coverage and consistency, not necessarily judgment on each individual citation.
The embedding and ranking layers are still improving
These numbers will move as we continue to tune the embedding model and ranking pipeline.
Why we evaluated the default product experience
A natural question is whether it is fair to compare systems that return very different numbers of papers.
We think it is — but only if the goal is understood correctly.
This is not an algorithm benchmark in the narrow academic sense. It is a product evaluation. The question is not: what happens if we force every system to return exactly the same number of papers? The question is: what does each tool actually hand a downstream AI agent when you ask a realistic biomedical question?
That is why we measured the default product experience: open the system, ask the question naturally, and record what it surfaces on the first response.
Claude and ChatGPT do not expose a "give me 20 PubMed papers" setting in the way a retrieval product does. Forcing them into that mold would change the thing being measured.
Seen that way, the comparison is meaningful for a few reasons:
- Precision is result-size agnostic. It measures how much of what was returned was relevant.
- F1 penalizes filler. Returning more papers only helps if those additional papers are relevant.
- Recall reflects the real downstream task. A tool that surfaces only a few relevant papers is genuinely less useful for evidence synthesis than one that surfaces many.
- Every system is scored against the same answer key. The ground truth is shared and independent of the systems being compared.
This is a product evaluation, not just a retrieval benchmark. If a product typically surfaces only a few papers, that is a real limitation for downstream scientific reasoning.
Claude and ChatGPT were accessed on April 8 and 9, 2026 to obtain the results evaluated here.
How we built the answer key
1. Start from expert synthesis
We began with published systematic reviews and meta-analyses. Expert authors had already spent significant time identifying the relevant literature for a specific biomedical question. Their reference lists formed the starting point for what a strong retrieval system should be able to find.
2. Generate realistic questions
For each review, we generated multiple forms of the same question: cleaner research-style prompts and messier user-style prompts closer to what appears in real product usage. That way the benchmark better reflects how biomedical users actually ask.
3. Pool candidates from multiple retrieval strategies
We then built a larger candidate pool using seven complementary approaches: the original review references, PubMed similar articles, direct keyword search, MeSH expansion, citation-network exploration, author co-occurrence, and related systematic reviews. This follows the basic logic of pooling used in information retrieval evaluation: combine results from diverse strategies so the judged set does not unfairly favor any one system. This is a variant of the pooling methodology that NIST's TREC benchmark has used since the early 1990. We use pooling here for the same reason TREC does: to avoid unfairly rewarding whichever single system we happen to use while building the answer key.
4. Grade and re-check the pool
Candidate papers were then graded on a three-level relevance scale: highly relevant, relevant, or not relevant. Pooling is not perfect, especially in very large corpora such as PubMed. So we added a pool-completeness check: if Amass retrieved highly ranked papers that had not yet been judged, those papers were added back into the judging queue. Every decision was retained with reasoning and could be reviewed by a human. The outcome was a graded answer key with explicit positive and negative judgments, designed so that systems could receive credit for retrieving genuinely useful papers that the original review might not have included.
Note that the dataset presented here is only a small subset of our production benchmarks.
How we normalized each tool's output
The systems being compared return evidence in different formats, so we normalized everything into the same scoring shape: an ordered list of PubMed IDs, ranked in the order each system surfaced them.
- Amass returned PMIDs directly from the BioMedCore pipeline.
- Claude with the PubMed connector returned citations linking to PubMed records, from which PMIDs could be extracted in order.
- ChatGPT with web search returned a mixture of PubMed links, journal pages, publisher pages, and other web sources. When a source mapped cleanly to a specific PubMed record via URL, DOI, or title, it was resolved to a PMID. Sources that could not be mapped to a PubMed record were dropped rather than scored as misses.
Rank order was preserved in every case, because the order in which papers appear matters both for evaluation and for downstream agent behavior.
We also only used the first, default response for each system without follow-up prompting for additional sources.
Why this matters beyond this benchmark
The broader point here is not just that Amass performed better on these ten questions.
It is that retrieval is still the hidden bottleneck in scientific AI.
As models improve, many people assume the problem will solve itself through better generation. But if the evidence layer remains thin or inconsistent, the system still begins from a narrow view of the literature.
That is why we have spent so much time building retrieval as core infrastructure rather than treating it as a side effect of generation.
If you want reliable scientific agents, the answer is not just a model that writes well. It is a retrieval layer that is built for the domain and dependable enough to serve as infrastructure.
See it in action — and what comes next
If you want to see how this works in practice, you can explore Amass today.
Amass is built to help researchers, clinicians, operators, and scientific teams work from a broader, more dependable evidence layer — whether the task is literature review, scientific diligence, target evaluation, clinical rationale building, or structured comparison across studies.
We are also preparing to expose this retrieval layer through both an API and an MCP server, so teams can plug it directly into their own tools, agents, and workflows.
Try Amass today: open the platform.
Talk to our team