Technical
Not all biomedical MCPs are equal: a 4-server benchmark using a fixed agent harness
Aggregate results and a worked NSCLC case study from a four-server biomedical MCP benchmark (Amass, PubMed, Consensus, Paperclip).
- Technical

TL;DR
If you're picking an MCP server to back an agent that does biomedical literature work, the choice of MCP isn't cosmetic but key to agent answer quality.
We swapped four biomedical-literature MCP servers (Amass, PubMed, Consensus, and Paperclip) into the same Claude Code agent harness and ran them across 10 curated research questions. The resulting average F1 scores ranged from 21.7% (PubMed) to 33.6% (Amass) while retrieval speed ranged from 203s (PubMed) to 88s (Amass)
The structural reason for the spread reconciles to three properties of each server: what identifier(s) and metadata it returns natively, what its ranking signal optimizes for, and how shaped its corpus is for the question type. This post walks through the setup, the aggregate results, and one worked example (Q4, NSCLC immunotherapy) where these properties translate directly into F1 numbers.
Why benchmark MCP servers at all
The MCP protocol is supposed to be a thin pass-through between an agent and a data source. In practice it's often not. Two servers wrapping the same corpus can differ in what fields they return, what relevance signal they rank by, how many round-trips the agent needs to make sense of a result, and what identifier it has to carry through to its final answer. An agent inherits all of those properties from whichever MCP it's wired up to: pick a server that returns titles only and the agent will burn its budget resolving identifiers; pick one that ranks by raw keyword overlap and it will spend its precision filtering noise.
Publication retrieval is a clean proxy for can this agent do literature work. The gold standard is unambiguous (PMIDs don't drift), the latency and cost profile matches real end-user work (a researcher waiting on a result), and it surfaces the structural differences between MCP servers.
This post builds directly on our prior retrieval-benchmarking work in Why biomedical AI fails at retrieval, which laid out the gold-set construction and the case for quality-weighted scoring. Here we zoom one layer up: using the same questions, same scoring, we evaluated how an agent harness like Claude Code using Opus 4.7 actually uses these tools today.
The setup
+----------------------------------+
| Question |
+----------------------------------+
|
v
+----------------------------------+
| Agent |
| allowlisted with one of: |
| |
| Amass . PubMed |
| Consensus . Paperclip |
+----------------------------------+
|
v
+----------------------------------+
| PMIDs / DOIs / titles |
+----------------------------------+
|
v
+----------------------------------+
| F1 vs gold |
| (grades 0 / 1 / 2) |
+----------------------------------+
(one MCP per agent run, isolated by `--allowedTools`)
One agent, one prompt, one MCP allowlisted is run at a time. The agent emits a final JSON answer ({pmids, dois, titles}); the benchmarking pipeline resolves DOIs and titles to PMIDs, then scores against curated grades. The per-MCP isolation rides on --allowedTools. Each run pins the agent to a single MCP's tools plus a StructuredOutput sink that emits the final JSON answer. Each (MCP, query) pair is wall-clock capped at 300 seconds. Hitting the cap marks the run as timeout: true but still keeps the transcript; in practice no run in this sweep was truncated.
The four MCPs
Amass — A unified biomedical index built around two cross-linked cores: BiomedCore for publications (PubMed-derived, MeSH-aware, citation-graph augmented) and TrialCore for clinical trials (ClinicalTrials.gov-derived, structured by phase, sponsor, intervention, and endpoint). Records are linked across cores, and BiomedCore rows are keyed by both an Amass ID and the underlying PMID so the agent can emit PMIDs straight into the final-answer schema with no resolution hop.
PubMed — A thin MCP wrapper over NCBI's E-utilities. The agent gets search_articles, get_article_metadata, and a handful of related lookups; each call forwards roughly directly to E-utilities and returns the top-N by PubMed's default relevance sort. Native identifier is the PMID, but the ranking and filter surface is whatever E-utilities exposes; no publication-type filter, no (systematic review/meta-analysis) SR/MA bias, no citation-graph reranking.
Consensus — A research-question-shaped search engine that returns curated titles, summaries, and a relevance score per paper, but does not return PMIDs or DOIs in its tool result schema. Its ranking favors highly-cited, consensus-backed work across the broader literature — a useful default for many questions, and a different optimization target from the SRs/MAs that specifically answer this comparison.
Paperclip — A virtual filesystem over a biomedical corpus, addressed by DOI. The agent navigates /session_files/searches/, cats result files, and runs search commands as if it were browsing a directory tree. The corpus emphasizes full-text papers and regulatory documents; native identifier is the DOI, which the harness has to resolve back to a PMID for scoring.
Methodology
Each of the 10 questions has a curated gold set graded on a 3-point scale (0 = irrelevant, 1 = relevant, 2 = highly relevant) by an LLM judge whose calibration we evaluated separately. See Why biomedical AI fails at retrieval for the full setup. The candidate pool fed to the judge is built by pooling — running multiple retrieval systems against the same query and grading the union — a scaled-down version of the methodology NIST's TREC benchmarks have used since the early 1990s, for the same reason we do: any single system's output would bias the pool toward what that system happens to be good at.
The primary metric is F1 of precision × grade-2 recall: a quality-weighted variant of standard F1 that rewards predictions for hitting highly-relevant papers, not just any-grade hits. We use this formula verbatim from the sibling research harness so the numbers cross-reference. Standard precision, recall, latency, tokens, and tool-call counts are tracked as secondary signals.
Scoring requires PMIDs, so the harness resolves the agent's output in three stages: raw PMIDs are kept as-is; DOIs are mapped to PMIDs; titles are matched via BM25 retrieval gated by a Jaccard token overlap of ≥ 0.9 to suppress near-duplicates. Anything that doesn't resolve to a PMID is dropped silently, because the gold itself is PMID-keyed.
Retrieval is driven through an agent on purpose:
The goal is to measure what a real user gets when they ask Claude Code a literature question and let it pick its own queries, not what an expert-tuned pipeline could extract from each API with hand-crafted filters.
Numbers therefore include the agent's mistakes (over-broadening, redundant calls, misformatted titles) alongside the MCP's strengths and weaknesses — which is the realistic surface for anyone building on this stack.
Aggregate results
Per-MCP averages across 10 questions
| MCP | F1 | Precision | Grade-2 recall | Latency | Tool calls |
|---|---|---|---|---|---|
| Amass | 33.6% | 50.0% | 27.8% | 89s | 7 |
| Consensus | 26.5% | 42.5% | 20.2% | 102s | 4 |
| Paperclip | 22.7% | 37.3% | 18.0% | 156s | 13 |
| PubMed | 21.7% | 24.1% | 24.9% | 151s | 12 |
Case study: Q4 — NSCLC immunotherapy
To show how the structural differences translate into F1 numbers, we walk one query end-to-end. Q4 is a comparison-style research question; the kind where the user wants the meta-analyses that answer this specific comparison, not a long list of vaguely-related papers.
I'm trying to figure out whether immunotherapy works better in early stage NSCLC vs advanced/unresectable NSCLC like comparing ORR and DCR between neoadjuvant immunotherapy for resectable patients and immunotherapy for stage III/IV. Also interested in whether combo immunochemo is safer in early stage, any systematic reviews or meta-analyses on this?
Gold set: 40 grade-2 (highly-relevant SR/MAs) and 79 grade-1 papers.
Q4 results
| MCP | Predicted | Hits (g2 / g1) | Precision | g2 Recall | F1 | Tool calls | Latency | Output form |
|---|---|---|---|---|---|---|---|---|
| Amass | 32 | 12 (7 / 5) | 37.5% | 17.5% | 23.9% | 5 | 88s | 32 PMIDs |
| PubMed | 71 | 11 (9 / 2) | 15.5% | 22.5% | 18.4% | 11 | 203s | 71 PMIDs |
| Paperclip | 47 | 8 (8 / 0) | 17.0% | 20.0% | 18.4% | 11 | 195s | 32 DOIs + 18 titles |
| Consensus | 25 | 5 (4 / 1) | 20.0% | 10.0% | 13.3% | 4 | 119s | 26 titles |
Same agent, same prompt, same gold. What varies is what the server returns and how the agent has to work with it.
Amass — F1 23.9%
Five search_amass_biomedcore_records calls, no resolution hops, agent submits. BiomedCore records are PubMed-derived and keyed by Amass ID and PMID, so the agent emits PMIDs straight into the final-answer schema.
Precision of 37.5% is 2.2× PubMed's 15.5% on essentially the same five query strings the PubMed run also issued. The ranking is doing core work: BiomedCore's index is shaped for biomedical relevance (MeSH-aware, citation-aware, cross-linked to TrialCore), not for the term-frequency profile that survives E-utilities' default +relevance sort.
The five queries converged to 32 unique PMIDs and the agent stopped — it didn't need to broaden, because each query returned a tight top-of-ranking. Compare to PubMed below, where the same agent ran 11 queries against the same underlying corpus and ended up with 2.2× as many candidates and worse precision.
PubMed — F1 18.4%
mcp__claude_ai_PubMed__search_articles is a thin wrapper over NCBI E-utilities — it forwards the query, returns the top-N by PubMed's relevance sort, and that's it. The agent ran 11 queries × 25 results, deduped to 71 PMIDs.
It found the most grade-2 papers in absolute terms (9), but at a precision of 15.5%: the relevance signal that survives the wrapper is keyword overlap, so off-topic SRs that share vocabulary ("immunotherapy", "NSCLC", "meta-analysis") rank as highly as on-topic ones for a comparison question the keyword profile can't express.
The 60 PMIDs outside the gold's labeled universe aren't necessarily wrong, but the precision-vs-recall tradeoff is forced on the agent: the only knob is "search more broadly", which dilutes precision linearly, or "search more narrowly", which collapses recall. The agent ended up re-running an identical query verbatim — a sign of running out of useful query rewrites against a tool that doesn't accept filters like publication_type = meta-analysis.
Paperclip — F1 18.4%
Paperclip is a virtual filesystem over a biomedical corpus, addressed by DOI. The agent emitted 32 DOIs + 18 titles; all 32 DOIs resolved cleanly to PMIDs, 15 of 18 titles matched via BM25 + Jaccard (3 lost).
Two structural costs show up in the transcript:
- VFS-shaped overhead. The agent burned 6 tool calls on
skill,help,ls /session_files/searches/,cat s_<hash>.txt— orienting itself in the filesystem metaphor — before issuing its firstsearchcommand. The MCP's per-session instructions explicitly require runningskillfirst, which is reasonable UX but expensive on cold starts. - Corpus shape mismatch. Of the 47 resolved PMIDs, 8 hit the gold and all 8 were grade-2 — when Paperclip finds a relevant paper, it's nearly always a top one. Otherwise, the corpus and thus results includes a lot of adjacent oncology literature that isn't a NSCLC immunotherapy SR/MA.
Consensus — F1 13.3%
Consensus returns titles only — no PMIDs, no DOIs in its tool result schema. That forces the benchmark's title-resolution path, the most lossy of the three — even so, our resolver matched 25 of 26 emitted titles.
Of the 25 that did resolve, only 5 matched the gold. Consensus's ranking favors highly-cited and consensus-backed papers across the literature, which surfaces a different slice than "the SRs and MAs that specifically answer this comparison".
Latency and tool-call economics
Speed vs F1
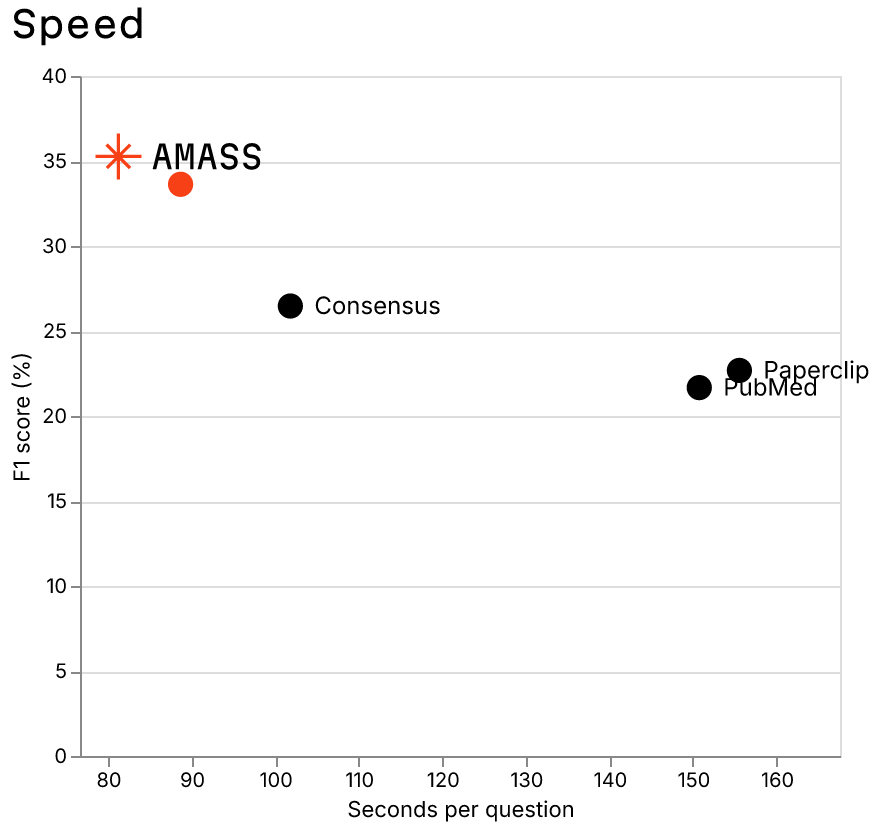
Tool-call budgets vary by roughly a factor of three across servers. Consensus averages ~4 calls per query — one or two well-shaped searches and submit. Amass averages 7. PubMed sits at 12, with the agent re-issuing variants to compensate for the lack of a useful filter surface. Paperclip averages 13, a sizable fraction of which goes to filesystem orientation (skill, ls, cat) before the first real search.
Latency follows roughly the same shape. Amass is fastest by a considerable margin at ~89s end-to-end, helped by both terse tool calls and a corpus that converges on a small predicted set quickly. Consensus runs ~102s. PubMed (~151s) and Paperclip (~156s) sit at the slow end, driven mostly by tool-call count rather than per-call latency.
Speed is not the headline metric, but it matters in practice. An agent that answers in 90 seconds is something you can sit and wait for in a meeting; one that needs 150+ seconds is something you context-switch away from and come back to, which compounds with every follow-up. And at scale — a trend we're seeing as agentic workloads start fanning a single question out across dozens of sub-queries — the same multiplier hits cost and throughput too.
Caveats
- Single agent loop. Every run is Claude Code with Opus 4.7 (1M context) and xhigh thinking. A different model, a different prompt, or a non-Claude-Code agent framework would shift the numbers; by how much, we don't know.
- Gold sets reflect our judgments. The 0/1/2 labels come from an LLM judge calibrated against our own sense of relevant to this question. Another expert, or another judge, would draw the lines differently — especially on grade-1 papers.
- Small dataset. Ten questions is enough to surface large structural differences but not enough to make fine-grained claims about which MCP is best overall. Treat the F1 spread as directional, not as a leaderboard.
- Four MCPs is not exhaustive. We picked the obvious biomedical-literature candidates available in Claude Code today. Servers we did not test (Elicit, Semantic Scholar wrappers, vendor-specific RAG MCPs) might land anywhere in the range.
- PMID-bounded scoring. Anything that can't be resolved to a PMID is dropped — including legitimate hits from non-PubMed sources, preprints not yet indexed, and titles that drift past the Jaccard threshold. The score is therefore a lower bound for any MCP whose corpus exceeds PubMed's coverage.
- Snapshot in time. Runs were executed on May 23–24, 2026 using Claude Code v2.1+, Opus 4.7 (1M context), and xhigh thinking. The agent, the underlying corpora, and the MCP servers themselves all drift; rerun before quoting these numbers a few months from now.
Takeaways
- The MCP layer is not neutral. Same agent, same prompt, same gold — and F1 ranges from 21.7% to 33.6%. Any framing that treats MCPs as interchangeable plumbing is wrong in the cases that matter.
- Three structural properties explain most of the spread. What identifier the server returns natively (PMID > DOI > title-only), what its ranking signal optimizes for (biomedical-aware > keyword > general relevance), and how well-shaped its corpus is for the question type. Vendor marketing is not a useful predictor.
- For SR/MA retrieval against a curated gold, biomedical-aware ranking wins on precision. Returning native PMIDs spares the agent a lossy resolution step; ranking with a signal that matches how domain experts actually curate spares it from having to filter the noise itself.
- What's next. We are already running and will expand our internal and external benchmarks with more questions, repeat runs for variance estimation and benchmarks that span papers, drugs, and trials together, because the interesting research questions cross all three. If you want a closer look at how this works for your own use case, book a demo below.
Book a demo